You see this:
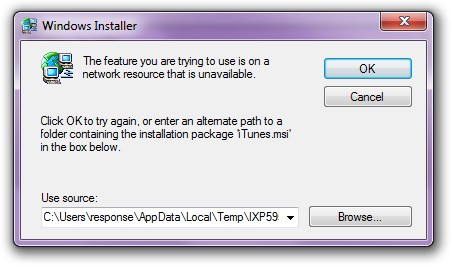
The feature you are trying to use is on a network resource that is unavailable. This is happening because the cached installer is missing (in my case due to running a scan on folder sizes, seeing this particular windows folder with all the uninstallers (the cache) and removing them.)
Use this:
http://support.microsoft.com/mats/Program_Install_and_Uninstall
Uninstall the program that is causing trouble using the tool and voila.
The feature you are trying to use is on a network resource that is unavailable. This is happening because the cached installer is missing (in my case due to running a scan on folder sizes, seeing this particular windows folder with all the uninstallers (the cache) and removing them.)
Use this:
http://support.microsoft.com/mats/Program_Install_and_Uninstall
Uninstall the program that is causing trouble using the tool and voila.
Comments